
Enterprise automation engineered for always-on operations
Legacy schedulers can’t keep pace with hybrid cloud complexity. RunMyJobs replaces fragmented, resource-heavy and manual disaster recovery (DR) processes with a single orchestration control plane, so your recovery workflows execute automatically, every time.
-

99.95% uptime SLA
A single control plane with 10x higher availability than other workload automation and orchestration platforms
-

SAP Endorsed App
The only orchestration platform in the RISE with SAP reference architecture, with out-of-the-box integrations for your stack
-

Global SaaS architecture
Broad global support, built-in disaster recovery and AI-driven monitoring — resilience by design, not by exception
-

AI-powered orchestration
Redwood RangerAI, agentic orchestration and MCP support for AI-ready workflows
-

Lower, predictable TCO
Consolidated tooling, reduced infrastructure costs and a zero-maintenance SaaS model
-

Security and auditability
SOC 1 & 2 Type 2-certified with complete audit trails for every recovery execution

End-to-end orchestration across your entire recovery lifecycle
RunMyJobs detects disruptions, sequences dependent workflows, executes failover across environments and validates recovery before handing back control. No manual steps. No database replication. No missed dependencies.
Whether you’re recovering from ransomware, a data center outage or human error, RunMyJobs gives your team the orchestration layer to meet recovery time objectives — without the manual coordination that slows everything down.
Where disaster recovery strategies fall short
Hybrid cloud environments span too many systems, clouds and regions for manual recovery to work reliably. These are the gaps that put your business at risk.
-

Manual recovery processes
Manual runbooks and fragmented tools break down under pressure. When outages hit, slow and error-prone recovery workflows mean every minute of coordination is another minute of downtime.
-
Hidden dependency fog
Without visibility into cross-platform dependencies, recovery workflows fail and critical workloads get missed, leaving gaps in your disaster recovery plan that only surface when it’s too late.
-
Fragmented tool sprawl
Disconnected tooling across environments means no single view of recovery readiness — and no consistent way to execute, test or validate your disaster recovery plan.
-
Missed RTO/RPO targets
As hybrid cloud complexity grows, complex DR architectural redundancy and manually coordinated failover and recovery processes can’t scale. Inconsistent execution puts recovery time objectives/recovery point objectives at risk.
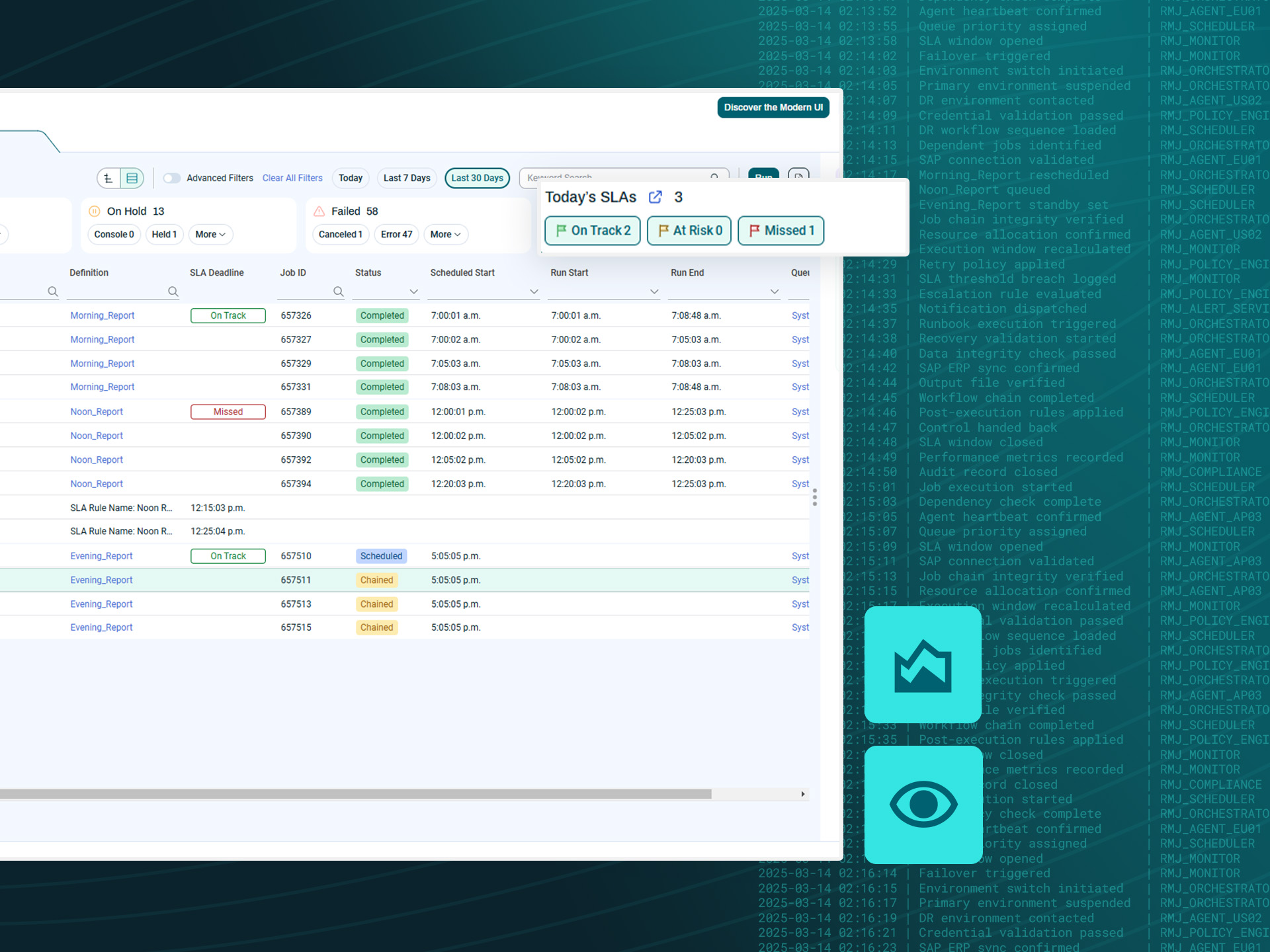
Real-time recovery readiness
Most teams don’t know their DR plan is broken until they need it. RunMyJobs gives you continuous visibility into recovery readiness — not just execution — so gaps surface during testing, not during an outage.
- Predictive SLA monitoring to flag risk upstream
- Scheduled, automated DR testing against live environments
- Real-time alerts during active recovery execution
- Complete audit trails for every workflow run
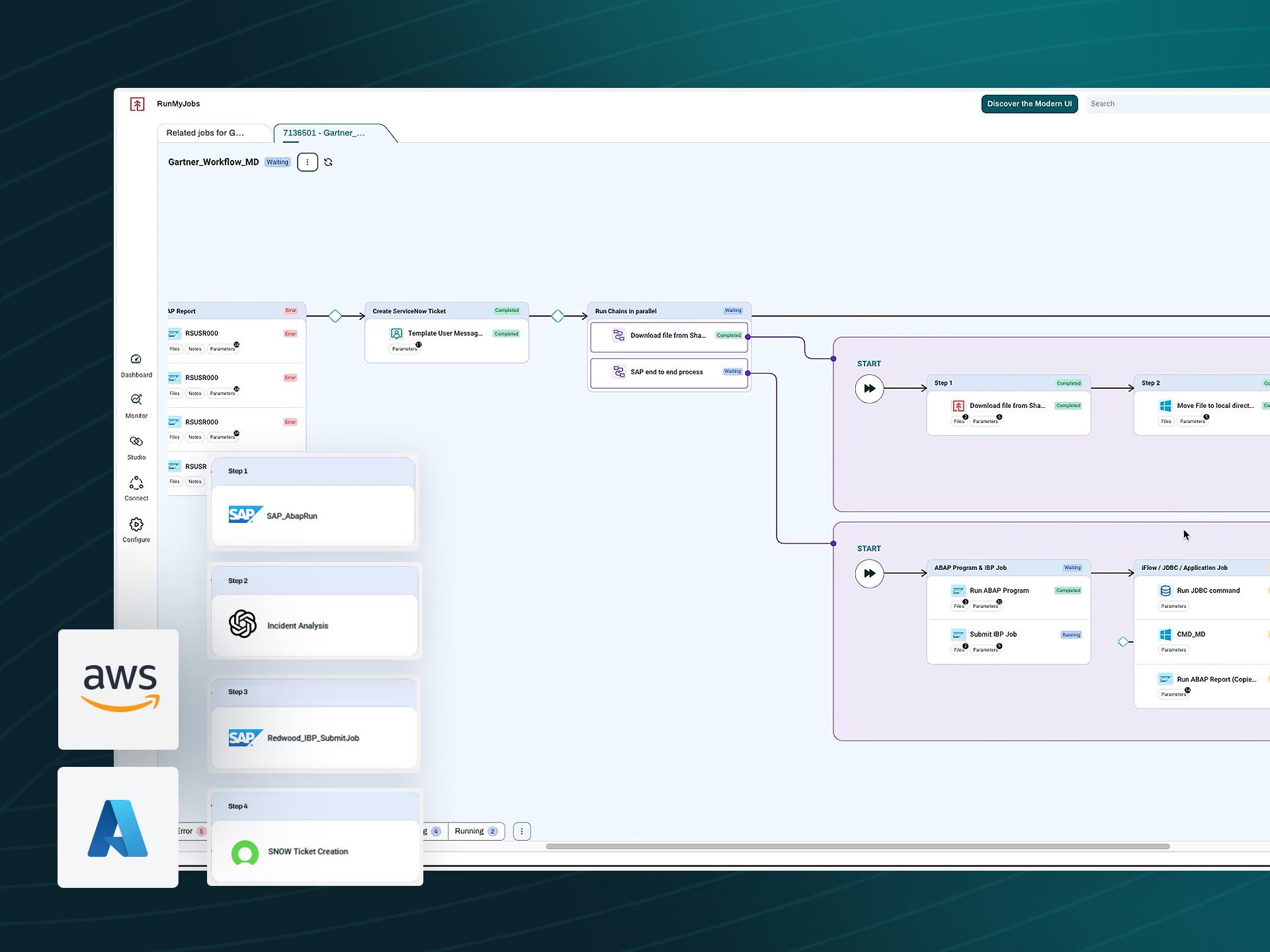
Automated failover across hybrid environments
Your recovery workflows don’t respect environment boundaries, and your orchestration shouldn’t either. RunMyJobs enforces consistent execution across all of them from a single control plane, with no environment-specific tooling required.
- On-premises: Policy-driven failover sequencing
- Cross-cloud: AWS and Azure workflow orchestration
- Multi-region: Coordinated fallback and validation
- VMware/virtual machines: Dependency-aware execution
Coordinate recovery across on-premises and cloud systems
The more environments in your stack, the more places recovery can break down. RunMyJobs gives you the controls to manage all of them from one place.
-

Unified orchestration
Get a single control plane for all recovery workflows, no matter how many environments, clouds or regions are in play.
-

Continuous DR readiness
Automate recovery testing on a schedule so your disaster recovery strategy is validated before disaster strikes, not after.
-

AI-powered remediation
AI-driven monitoring detects disruptions, diagnoses root causes and triggers corrective actions, often before your team is alerted.
-

Freedom from silos
Break down the disconnected tooling and manual runbooks that make DR plans unreliable in complex hybrid cloud environments.
-

Predictive resilience
AI-driven SLA monitoring identifies upstream risks to downstream recovery outcomes before they cause downtime or data loss.
-

Built-in compliance
Complete audit trails and governance controls make every recovery execution provable — critical for regulated industries.

Disaster recovery as part of a strong hybrid cloud strategy
Reliable recovery depends on reliable operations. RunMyJobs unifies orchestration across your entire hybrid estate, so the same control plane that automates your DR workflows also keeps your day-to-day operations running without disruption.
From event-driven workloads to ERP integrations, cross-cloud orchestration to phased application modernization, RunMyJobs is the strategic platform that leading enterprises rely on to manage hybrid cloud complexity at scale.
How automated workflows become intelligent outcomes
RunMyJobs moves beyond predefined tasks to goal-driven automation. Orchestrate intelligent agents within the enterprise-grade governance framework your mission-critical recovery processes demand.

The path forward
Learn how AI-driven orchestration is redefining resilience and how leading enterprises are moving beyond reactive recovery to autonomous, always-on operations.
RunMyJobs keeps hybrid cloud enterprises running
Disaster recovery is one piece of a broader operational resilience story.
-
Use case
Event-driven automation
Learn MoreSynchronize legacy batch workloads with real-time cloud services for reliable business execution.
-
Use case
ITOps and AIOps
Learn MoreDetect, diagnose and remediate IT operations failures before they impact your business.
-
Use case
ERP and SaaS
Learn MoreOrchestrate ERP systems, SaaS apps and custom workflows from a single, dependency-aware production platform.
-
Use case
Data pipeline orchestration
Learn MoreManage complex data pipeline dependencies across hybrid environments with end-to-end visibility.

Integrate across your hybrid cloud ecosystem
RunMyJobs connects to the platforms your hybrid cloud operations depend on, with hundreds of out-of-the-box connectors across cloud, ERP, data and infrastructure technologies.
Keep learning
From ITOps fundamentals to cloud-first automation strategy, explore the concepts that matter most for enterprise resilience.




Disaster recovery automation and orchestration FAQs
What is disaster recovery orchestration?
Disaster recovery orchestration (DR orchestration) is the automated coordination of recovery workflows — failover sequencing, dependency resolution, cross-environment execution — so critical systems come back online consistently and quickly. Rather than relying on manual runbooks that break under pressure, orchestrated disaster recovery processes use a centralized control plane to execute predefined recovery policies automatically.
RunMyJobs by Redwood delivers this as a core capability. Its disaster recovery orchestration engine maps application dependencies, automates failover across on-premises and cloud environments and provides end-to-end visibility so teams can validate recovery readiness before a disruption occurs — not during one.
How does automated disaster recovery improve recovery time objectives?
Automated disaster recovery reduces the time it takes to restore critical systems by eliminating manual steps that slow recovery execution. Every minute spent locating runbooks, coordinating across teams or manually re-sequencing workflows is a minute of downtime. Automation removes that lag, initiating recovery workflows immediately, in the right order, with the right dependencies resolved.
RunMyJobs by Redwood orchestrates automated recovery workflows with full dependency awareness and real-time monitoring, giving enterprises the metrics and visibility needed to hit their recovery time objectives. It also enables continuous recovery testing so teams know their recovery time objectives (RTO) targets are achievable before a real outage puts them to the test. As workloads and environments grow, RunMyJobs ensures your automated disaster recovery scales with the business.
What is disaster recovery failover in hybrid environments?
Disaster recovery failover in hybrid environments is the process of switching critical applications and workloads from a failed primary environment — whether on-premises, a data center, or a cloud region — to a healthy secondary environment. In hybrid cloud architectures, this spans multiple platforms, providers and regions, making automated failover orchestration essential.
Unlike DRaaS solutions that focus on infrastructure replication alone, RunMyJobs by Redwood automates failover and failback across on-premises systems, AWS, Azure and multi-cloud environments. It sequences recovery workflows based on application dependencies, enforces recovery policies and provides real-time visibility into execution, so full system functionality can be restored quickly and consistently.